

Video
Why Telcos Need to Move to the Public Cloud
In this 10-minute talk I delivered at GSMA Thrive North America in October, I unpack why telcos need to migrate to the public cloud – the massive savings opportunity.
One thing people don’t talk about enough when they talk about the public cloud is how you can completely eliminate millions of lines of code. Recently, I spoke at GSMA Thrive Americas where one of my ways to dramatically reduce costs by moving to the public cloud was to reduce legacy source code by 100x.
100x! How insane is that? How on earth does that happen? It happens when you refactor software. One big problem I see with everyone’s rush to label things “cloud-native” (🙄) is how everyone equates putting something in Kubernetes as suddenly becoming cloud-native with one simple action. Newsflash: it’s not. Let’s discuss why.
Kubernetes is cloud-native. And *I guess* if you put an application in a Kubernetes container and run it in a cloud, public or otherwise, then yes, your application is sort of cloud-native, too. It is cheating, though. You didn’t really modify your application much to make it cloud-native. I’d bet the difference between an application like this and the same application running on bare metal is pretty minimal. Code base-wise, I bet it’s 99% the exact same code. You have to look under the hood and really understand what is going on at a technical-architecture level, at a code level, with the product to make it *truly* cloud native. Let’s talk about what I mean when I say cloud-native, and how it’s different than what I see most other people doing.
When I say cloud native, running on the public cloud – I am talking about ripping out huge components of software code and replacing them with one line of code calling out to software built by the public cloud vendors. With that simple action, what was hundreds or thousands of lines of code, just GOES AWAY. So let’s expound on that example I talked about in my GSMA Thrive Americas talk.
True story: a few weeks ago I spoke with a software vendor with a 20-year-old product. Because it was built 20 years ago, many tools, libraries, and components that the original software team needed simply did not exist. So what happened? They wrote it themselves. (This is not uncommon.) And so over the course of 20 years of major releases, maintenance, and upgrades, the product had grown to more than 1 million lines of source code. To get an idea of how much code that is, check out this old-but-cool infographic, which has a good visual of how many lines of code it takes to power some well-known applications and services.
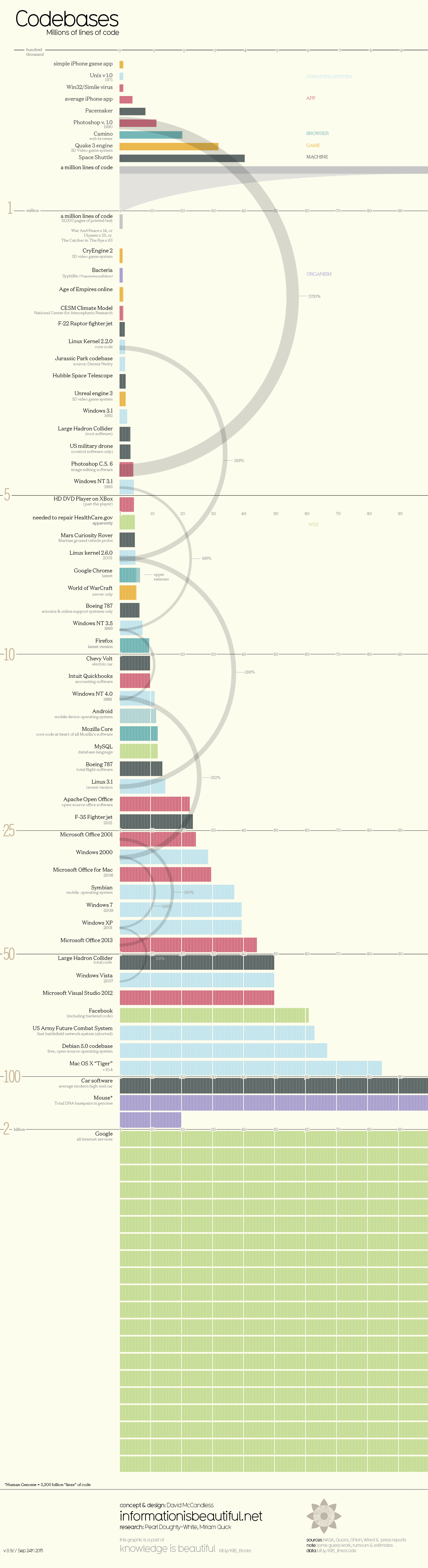
Now, imagine new software developers being hired into this company to support this exciting (?) but also very old 20-year-old product: they now need to get to know one-million lines of code. With each new developer working on the code, and with so many entry points, there’s ample opportunity to introduce new defects by newbie developers. Since it’s really hard to know every single line of code, developers start taking shortcuts to resolve issues as quickly as possible. You get code duplication. And so your code base starts growing, probably at least 15% with each upgrade, and you can see what a mess this creates over time. Remember, this is just one product! For telcos with a thousand applications, a thousand codebases – this unchecked growth is a serious issue. It’s kinda like, dare I say, a PANDEMIC.
Fortunately, there’s a new way to tackle this problem. I know you’ll be shocked to hear it when I say: THE PUBLIC CLOUD.
So, back to my example. This company I’m talking about wanted to make its product available on the public cloud. It would have been super easy to dump it into a Kubernetes container, label it “cloud-native,” and declare it available on GCP and AWS. Done and dusted, one-million lines of code in K8s, running on two public clouds. Sounds great, right?
Wrong. They still had one-million lines of legacy code to maintain. Thankfully, some smart engineers looked at the software available on the public cloud and found Firebase from GCP. By leveraging Firebase they eliminated 996,500 lines of code and delivered the product in just 3,500 lines of code. That’s it. Almost a million lines of code DELETED, just like that.
This move introduced a new problem, though: what about AWS? Firebase isn’t available on AWS. Again, thankfully they did some research and found a similar solution to replace Firebase over at AWS and were able to provide the same solution for 6,000 lines of code.
Ask yourself what’s better: one-million lines of code with Kubernetes, or two different code bases – one 3,500, one 6,000 – for a total of 9,500 lines of code to support? Hopefully, you’re like me and realize removing 990,500 lines of code is a WAY BETTER IDEA. It increases the maintainability, it’s easier to learn, it offers less opportunity to introduce bugs – all around it’s a way better approach. These guys didn’t fret about vendor lock-in with GCP, or worry that they had two different codebases on two different clouds. They now support less than 1% of the original code base and that is a way better situation.
Clearly, reducing code should be a goal for your organization. How many lines of code do you think your organization and your applications are running on? But also ask yourself: how many millions of lines of code could you eliminate in your organization? How much more streamlined could your products and programs be? How much could you save – in time, money, and headcount?
Code reduction is possible now because the tools are readily available: there’s been fantastic advancement in the space of business applications by the hyperscalers. BUT YOU NEED TO MOVE YOUR APPLICATIONS TO THE PUBLIC CLOUD. Telcos can use these business applications within their own applications and replace thousands/millions of lines of code with a single callout line and make their applications truly cloud native.
If telcos did this, I think they could reduce their source code by 100x. They would dramatically simplify their applications and reduce the opportunity to introduce defects with each change. It would be easier to modify and upgrade.
With simpler codebases, telcos will need less people to support it. With less people needed to manage the code bases, employees have more time to work on high impact, strategic projects that lead to higher job satisfaction and engagement. It’s a win-win.
Refactoring code is not an easy task. On the scale of difficulty when moving applications to the public cloud, it’s probably one of the most difficult moves because of all the complexity and change it introduces to an application. You’re definitely going to need a highly skilled team that knows how to do this the right way.
Replacing thousands of lines of code with hyperscaler business applications means undoing lots of work that may have taken your developers decades – and millions of dollars – to create. You would think this would be a great task suited for the original architect of the code (they know it so well!) but I will caution you on this approach. I have found that it’s practically impossible to get the original architect of a product to refactor their own code. In their mind, their creation is perfect. And asking the architect of a software solution to cut hundreds, thousands – millions! – of lines of legacy code is kind of like telling a parent their baby is ugly. It’s really hard for them to rip up and throw away their hard work. My suggestion is to create a new team that doesn’t have the emotional attachment to the code so they can objectively review it with fresh eyes and make harsh decisions to delete as much as possible.
There are some other great examples of refactoring – you could refactor databases by removing all your dependency on the legacy, expensive, on-premise databases like (AHEM) Oracle. You can be like Verizon Wireless, the second biggest wireless communications service provider in the US, and use Google Contact Center AI to improve customer support with advanced natural language understanding, high fidelity synthetic voice to humanize the conversation, and a virtual assistant able to handle five times the number of questions in the same conversation. Or you could be like Lebara, founded in 2001 and now one of Europe’s fastest growing mobile companies. It used AWS’ machine learning tool SageMaker to detect new cases of fraud and identify further opportunities for fraud detection – all within just three days of adopting the solution!
This is what I mean by being cloud-native. It’s all about using the software of the public cloud to refactor legacy applications with technology built by the world’s best engineers. It’s not just about using elastic compute. It’s not just about using Kubernetes. It’s about completely rethinking how you design and deliver software solutions inside a telco organization with the software of the public cloud.
It’s just sitting out there waiting for you to make the first move.
Need help refactoring your applications? Contact me – I can help!
Recent Posts

 Get my FREE insider newsletter, delivered every two weeks, with curated content to help telco execs across the globe move to the public cloud.
Get my FREE insider newsletter, delivered every two weeks, with curated content to help telco execs across the globe move to the public cloud.

